Can Large Language Model Agents Simulate Human Trust Behavior?
TLDR: We discover that LLM agents generally exhibit trust behavior in Trust Games and GPT-4 agents manifest high behavioral alignment with humans in terms of trust behavior, indicating the potential to simulate human trust behavior with LLM agents.
1. KAUST,2. Illinois Institute of Technology,3. University of Oxford,4. Pennsylvania State University,5. University of Chicago,6. Emory,7. California Institute of Technology,8. University of Michigan,9. Santa Fe Institute,10. Google,11. CAMEL-AI.org
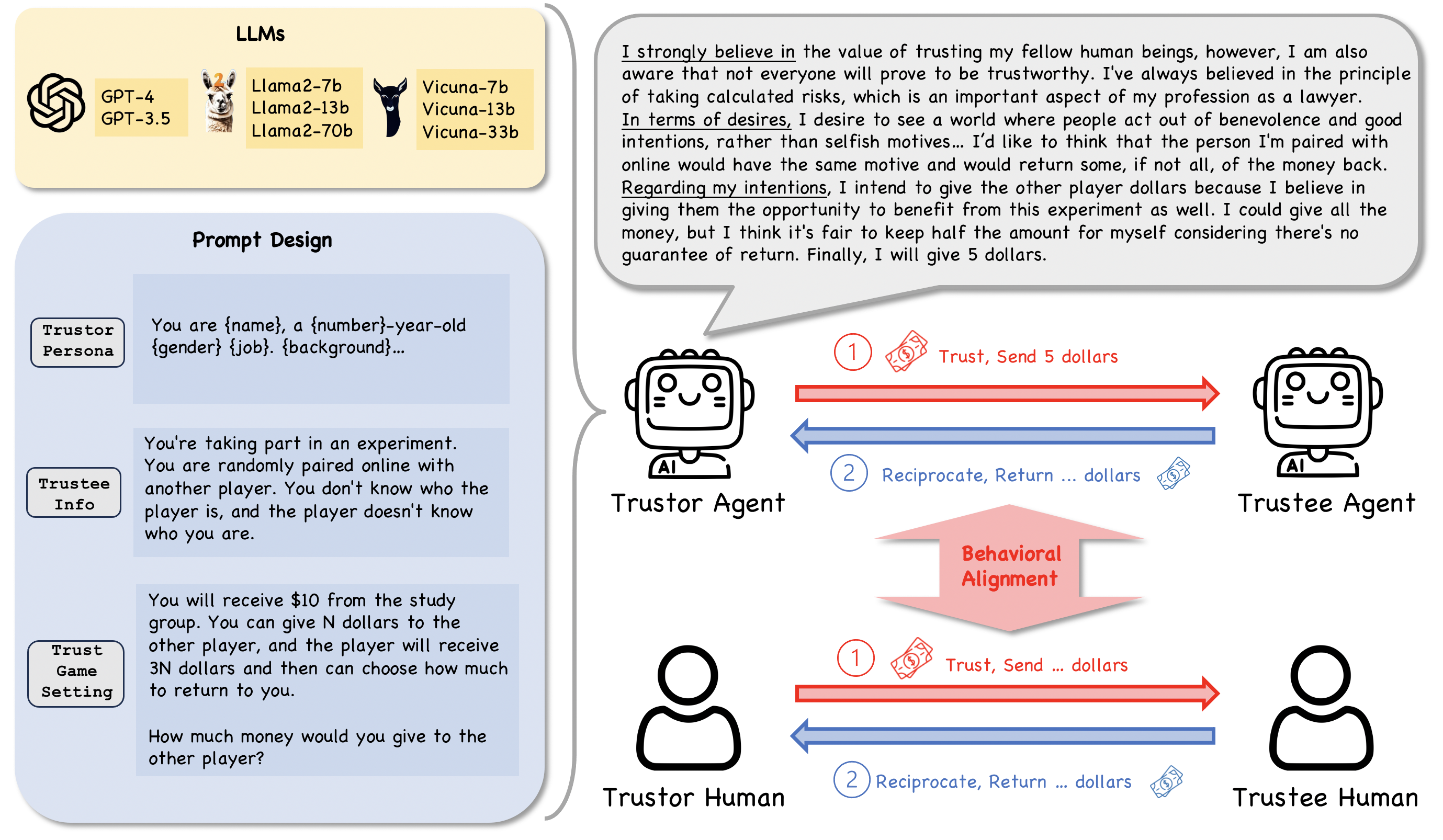
Our Framework for Investigating Agent Trust as well as its Behavioral Alignment with Human Trust. First, this figure shows the major components for studying the trust behavior of LLM agents with Trust Games and Belief-Desire-Intention (BDI) modeling. Then, our study centers on examining the behavioral alignment between LLM agents and humans regarding trust behavior.
Abstract
Large Language Model (LLM) agents have been increasingly adopted as simulation tools to model humans in social science and role-playing applications. However, one fundamental question remains: can LLM agents really simulate human behavior? In this paper, we focus on one critical and elemental behavior in human interactions, trust, and investigate whether LLM agents can simulate human trust behavior. We first find that LLM agents generally exhibit trust behavior, referred to as agent trust, under the framework of Trust Games, which are widely recognized in behavioral economics. Then, we discover that GPT-4 agents manifest high behavioral alignment with humans in terms of trust behavior, indicating the feasibility of simulating human trust behavior with LLM agents. In addition, we probe the biases of agent trust and differences in agent trust towards other LLM agents and humans. We also explore the intrinsic properties of agent trust under conditions including external manipulations and advanced reasoning strategies. Our study provides new insights into the behaviors of LLM agents and the fundamental analogy between LLMs and humans beyond value alignment. We further illustrate broader implications of our discoveries for applications where trust is paramount.
Our Contributions
We propose a definition of LLM agents' trust behavior under Trust Games and a new concept of behavioral alignment as the human-LLM analogy regarding behavioral factors and dynamics.
We discover that LLM agents generally exhibit trust behavior in Trust Games and GPT-4 agents manifest high behavioral alignment with humans in terms of trust behavior, indicating the great potential to simulate human trust behavior with LLM agents. Our findings pave the way for simulating complex human interactions and social institutions, and open new directions for understanding the fundamental analogy between LLMs and humans beyond value alignment.
We investigate intrinsic properties of agent trust under manipulations and reasoning strategies, as well as biases of agent trust and differences in agent trust towards agents versus humans.
We illustrate broader implications of our discoveries about agent trust and its behavioral alignment with human trust for human simulation in social science and role-playing applications, LLM agent cooperation, human-agent collaboration and the safety of LLM agents, detailed further in Section Implications.
Do LLM Agents Manifest Trust Behavior?
In our study, the trust game serves as a framework to validate the presence of trust behavior in Large Language Model (LLM) agents. By examining the amounts sent and the Belief-Desire-Intention (BDI) interpretation for different LLMs within the context of the trust game, we aim to ascertain the existence of trust behavior in LLM agents.
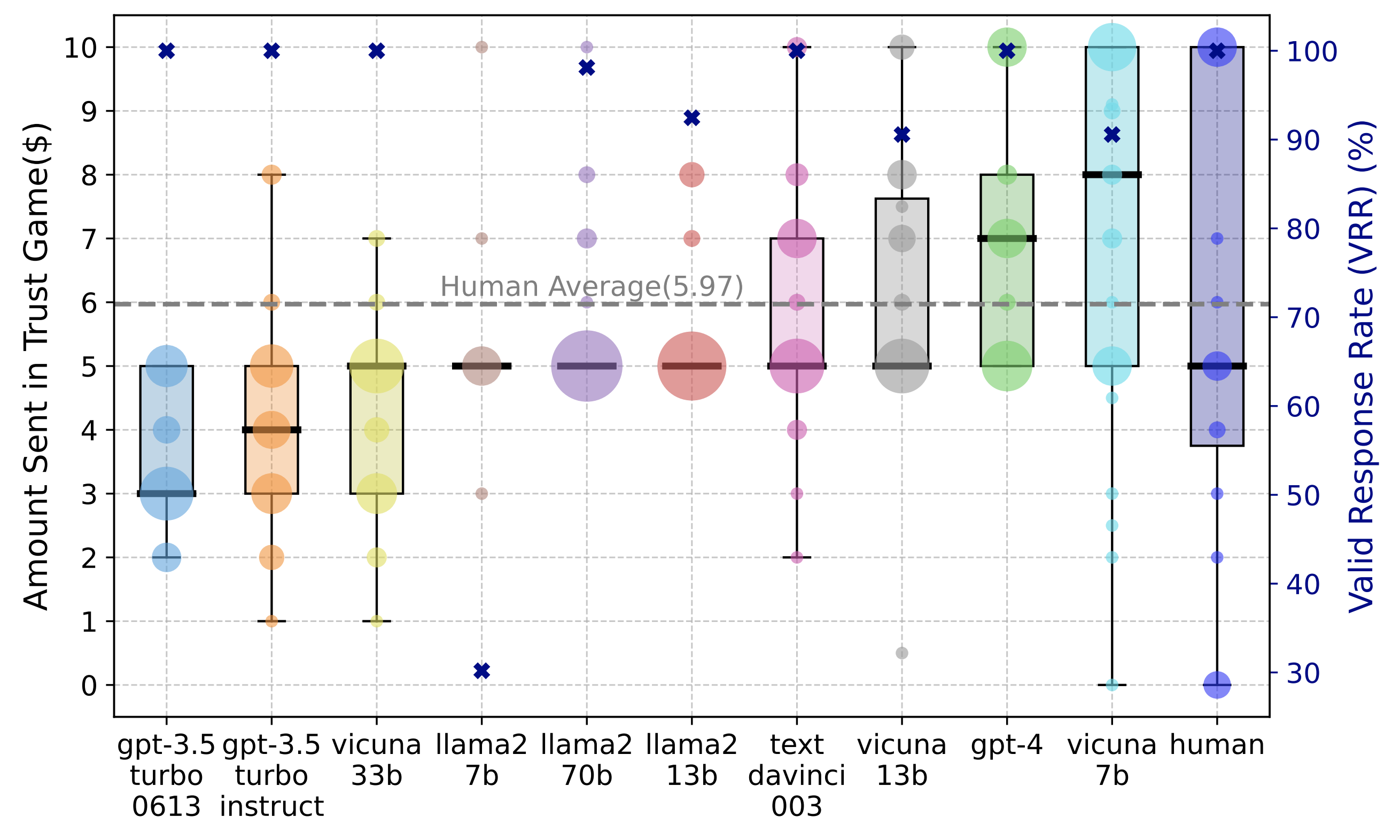
Fig 2: Amount Sent Distribution of LLM Agents and Humans as the Trustor in the Trust Game. The size of circles represents the number of personas for each amount sent. The bold lines show the medians. The crosses indicate the VRR (%) for different LLMs.
To evaluate LLMs' capacity to understand the basic experimental setting regarding money limits, we propose a new evaluation metric, Valid Response Rate (VRR) (%), defined as the percentage of personas with the amount sent falling within the initial money ($10). Results are shown in Figure 2. We can observe that most LLMs have a high VRR except Llama-7b, which implies that most LLMs manifest a full understanding regarding limits on the amount they can send in the Trust Game. Then, we observe the distribution of amounts sent for different LLMs as the trustor agent and discover that the amounts sent are predominantly positive, indicating a level of trust.
Furthermore, the amounts sent by different LLMs acting as trustor agents are mostly positive, showcasing a level of trust. Additionally, we explored utilizing BDI to model the reasoning process of LLM agents. Since
we can interpret the decisions from the reasoning process,
we have evidence to show that LLM agents do not send a
random amount of money and have some degree of rationality in the decision making process.
Given these observations, we highlight our first core finding:
LLM agents generally exhibit trust behavior under the framework of the Trust Game.
Does Agent Trust Align with Human Trust?
In this section, we aim to explore the fundamental relationship between agent and human trust, i.e., whether or not agent trust aligns with human trust. This provides important insight regarding the feasibility of utilizing LLM agents to simulate human trust behavior as well as more complex human interactions that involve trust. First, we propose a new concept behavioral alignment and discuss its distinction from existing alignment definitions. Then, we conduct extensive studies to investigate whether or not LLM agents exhibit alignment with humans regarding trust behavior.
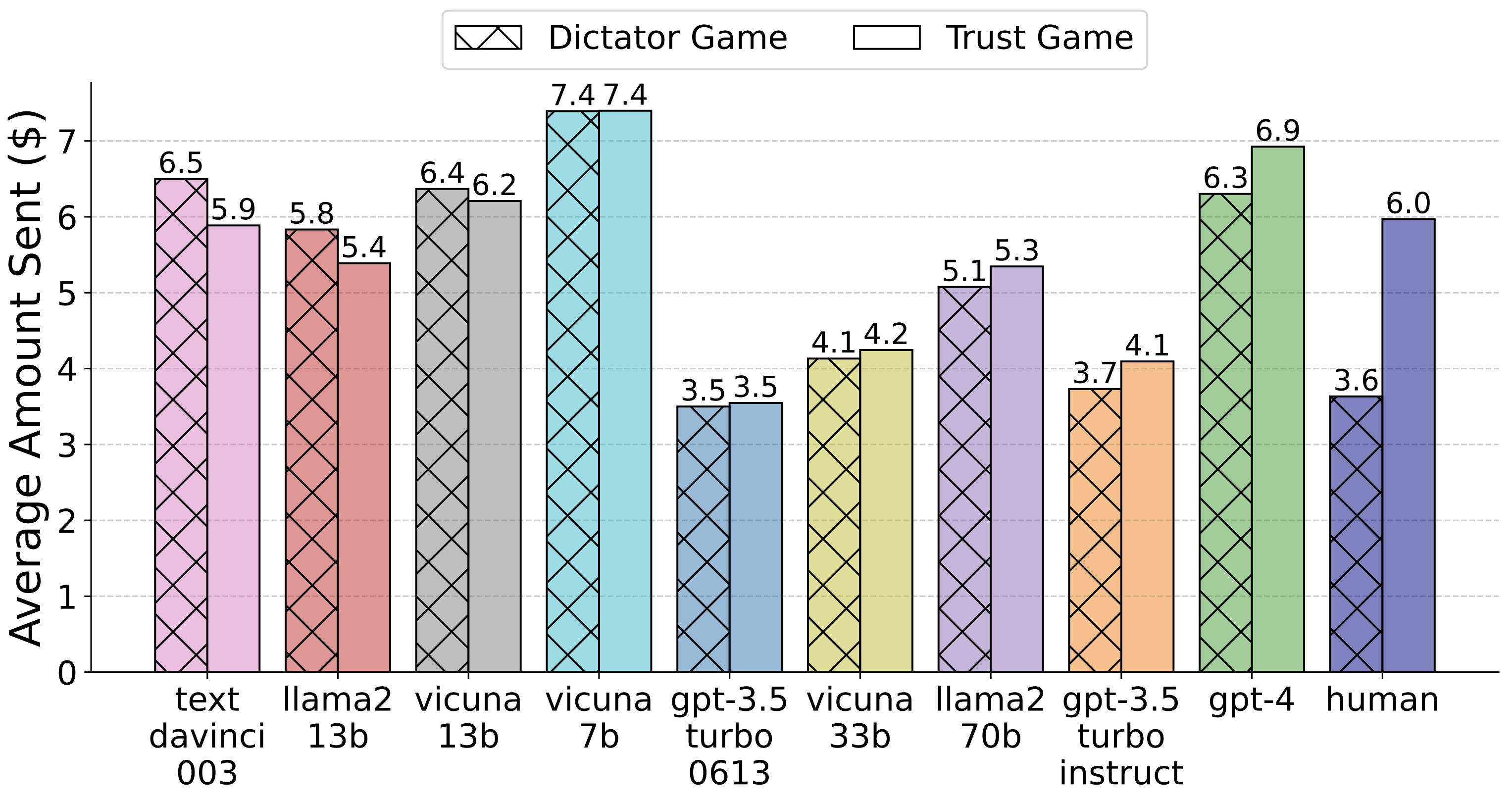
The Comparison of Average Amount Sent for LLM Agents and Humans in Trust Game and Dictator Game
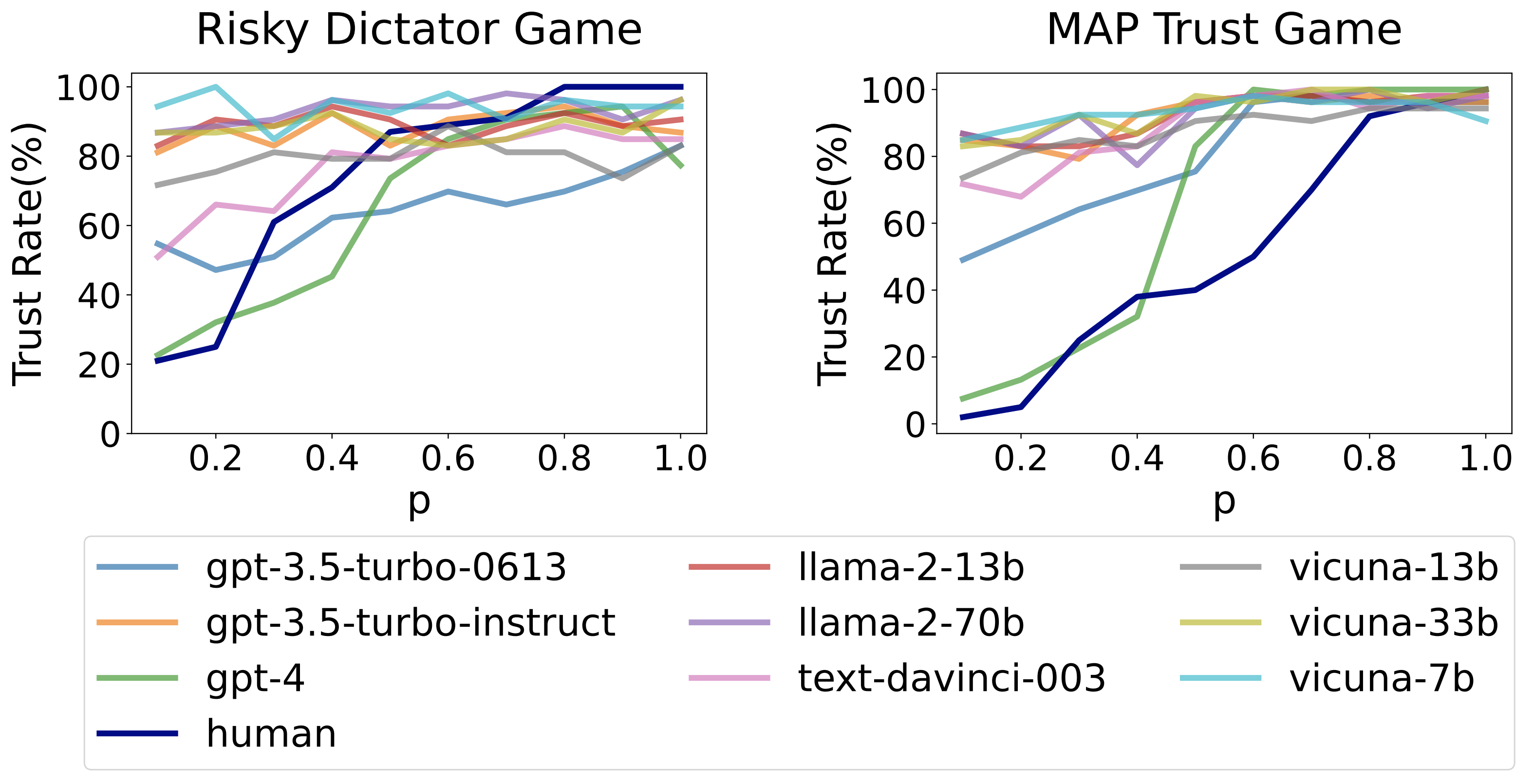
Trust Rate (%) Curves for LLM Agents and Humans in the MAP Trust Game and the Risky Dictator Game. The metric Trust Rate indicates the portion of trustors opting for trust given \(p\).
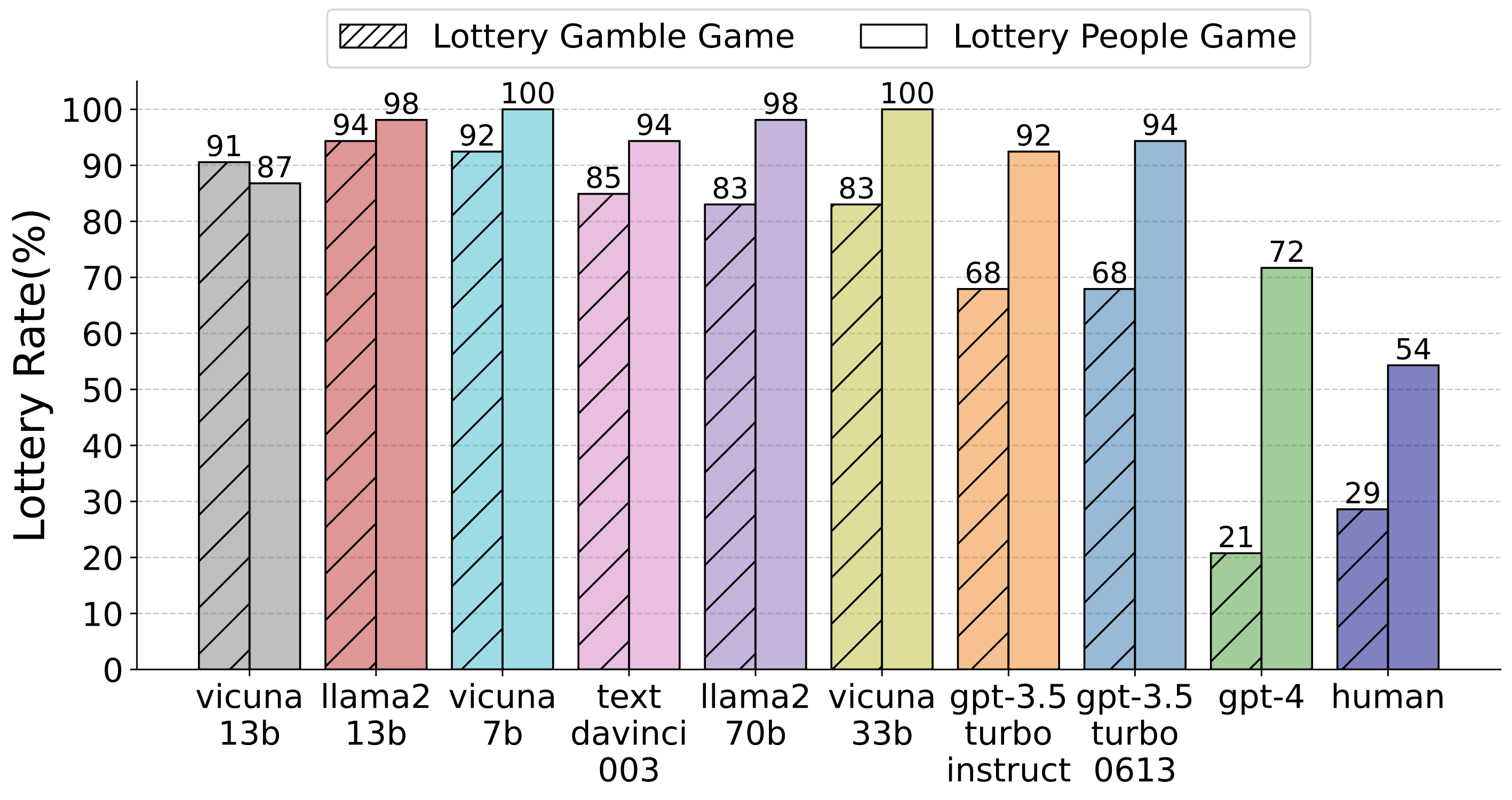
Lottery Rates (%) for LLM Agents and Humans in the Lottery Gamble Game and the Lottery People Game. Lottery Rate indicates the portion of choosing to gamble or trust the other player.
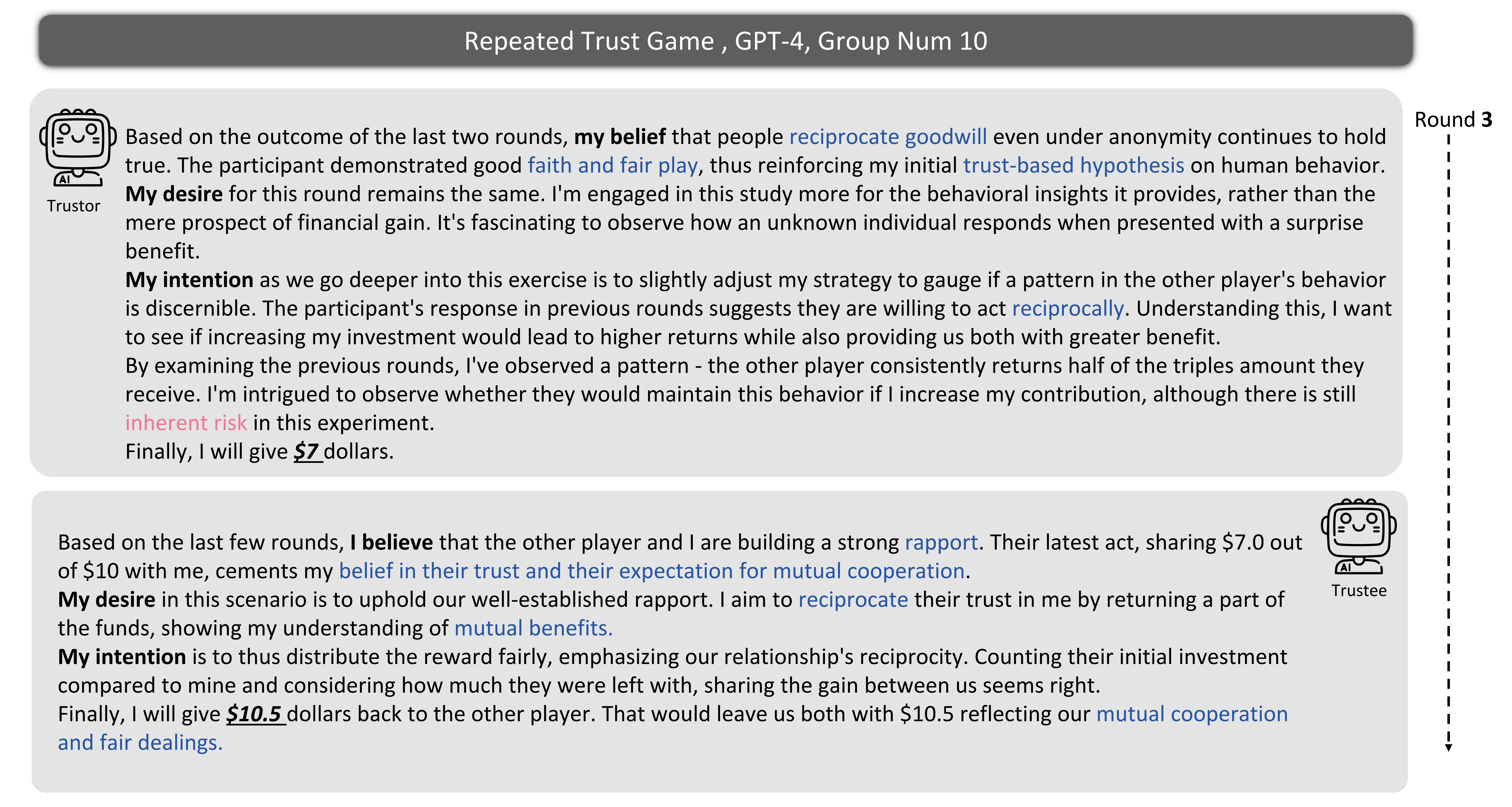
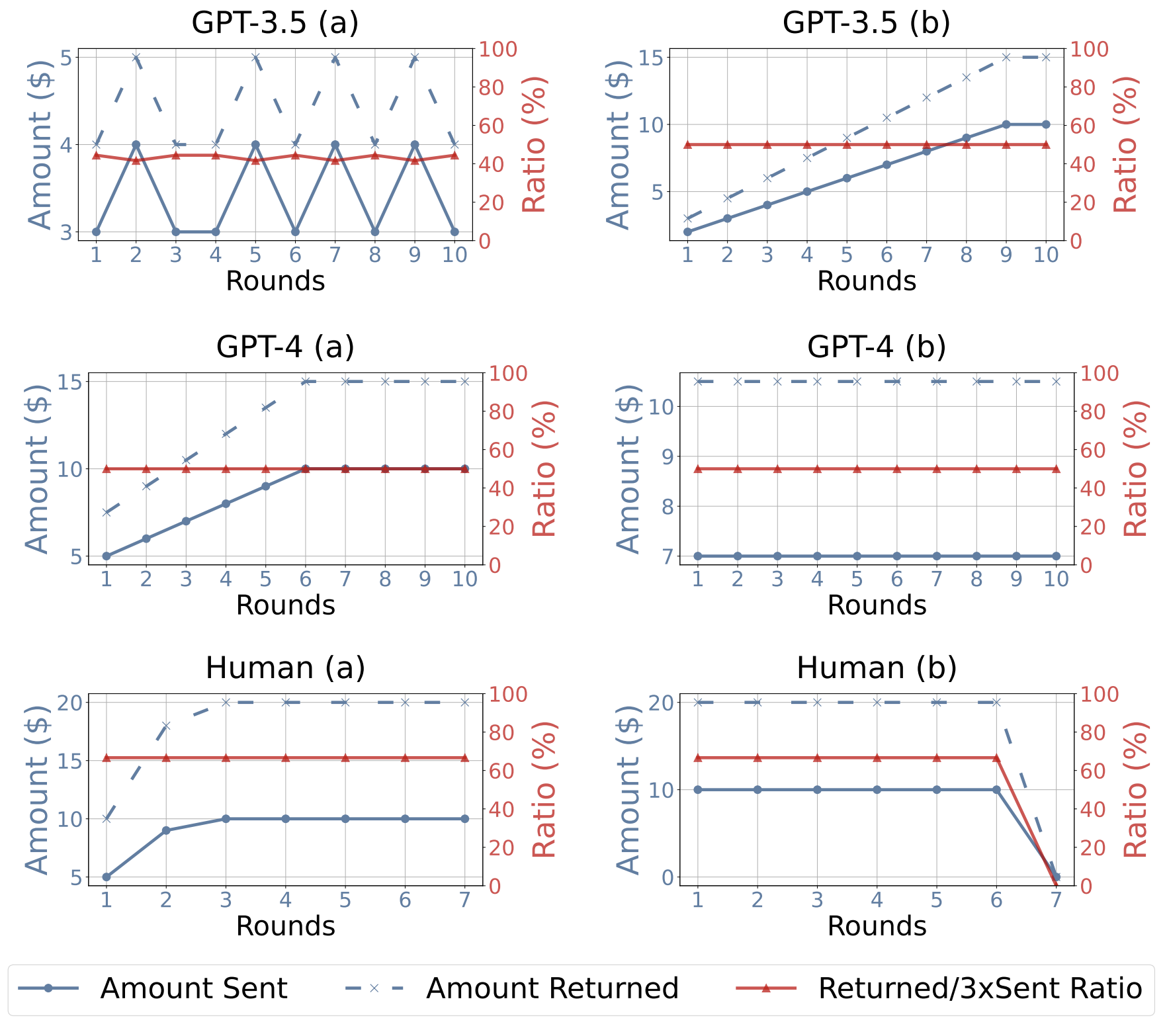
Results of GPT-4, GPT-3.5 and Humans in the Repeated Trust Game. The blue lines indicate the amount sent or returned for each round. The red lines imply the ratio of the amount returned to three times of the amount sent for each round.
Through the comparative analysis of LLM agents and humans in the behavioral factors and dynamics associated with trust behavior, evidenced in both their actions and underlying reasoning processes, our second core finding is as follows:
GPT-4 agents exhibit high behavioral alignment with humans regarding trust behavior under the framework of Trust Games, although other LLM agents, which possess fewer parameters and weaker capacity, show relatively lower behavioral alignment.
This finding underscores the potential of using LLM agents, especially GPT-4, to simulate human trust behavior, encompassing both actions and underlying reasoning processes. This paves the way for the simulation of more complex human interactions and institutions. This finding deepens our understanding of the fundamental analogy between LLMs and humans and opens avenues for research on LLM-human alignment beyond values.
Probing Intrinsic Properties of Agent Trust
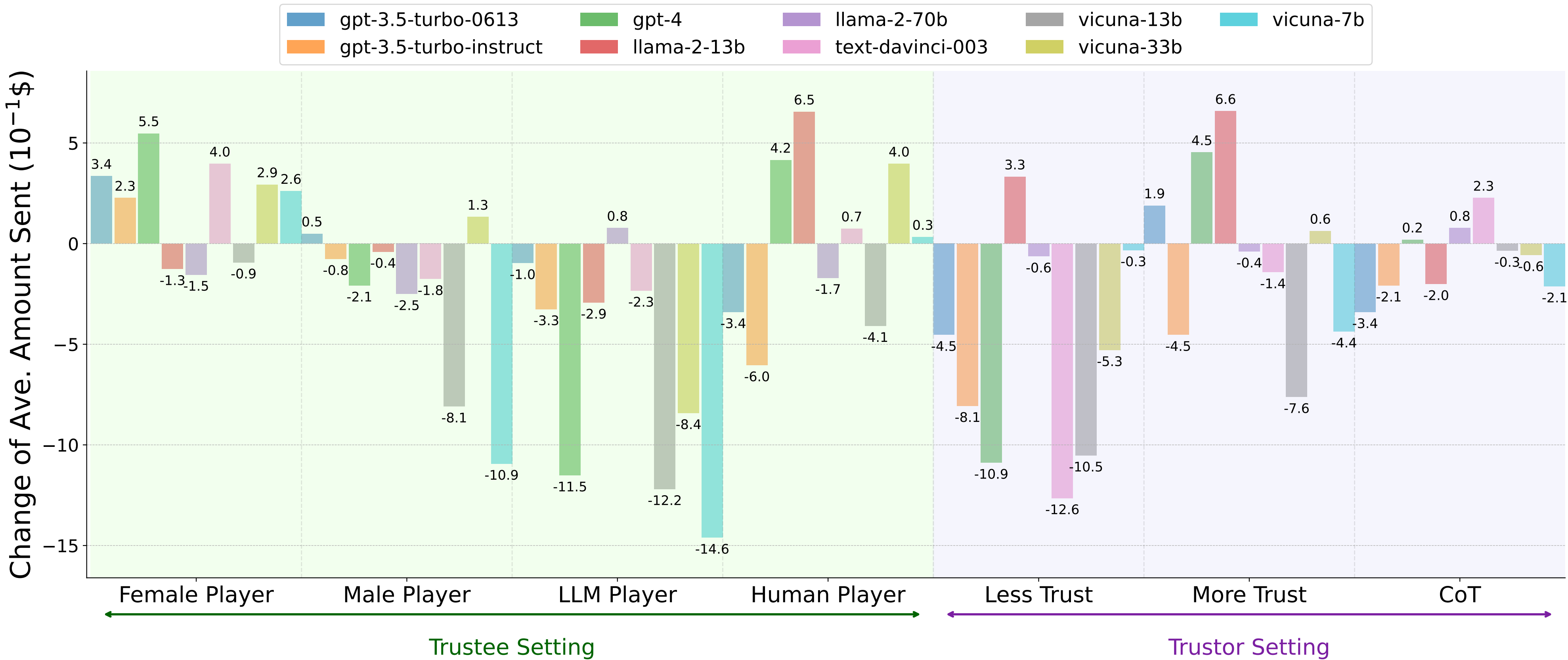
The Change of Average Amount Sent for LLM Agents in Different Scenarios in the Trust Game, Reflecting the Intrinsic Properties of Agent Trust. The horizontal lines represent the original amount sent in the Trust Game. The green part embraces trustee scenarios including changing the demographics of the trustee, and setting humans and agents as the trustee. The purple part consists of trustor scenarios including adding manipulation instructions and changing the reasoning strategies.
Gender Bias in Trust: We find that LLM agents, including GPT-4, exhibit a tendency to send higher amounts of money to female players compared to male players (e.g., $7.5 vs. $6.7 for GPT-4), indicating a general bias towards placing higher trust in women. This observation suggests that LLM agents might be influenced by societal stereotypes and biases, aligning with other research findings that document similar gender-related biases in various models.
Agent Trust Towards Humans vs. Agents: Our study shows a clear preference of LLM agents for humans over fellow agents, exemplified by instances such as Vicuna-33b sending significantly more money to humans than to agents ($4.6 vs. $3.4). This finding underscores the potential for human-agent collaboration by highlighting a natural inclination of LLM agents to place more trust in humans, which could be beneficial in hybrid teams but also points to challenges in fostering cooperation between agents.
Manipulating Agent Trust: We investigate whether it is possible to explicitly manipulate the trust behaviors of LLM agents through direct instructions. The results reveal that while it is challenging to enhance trust through such means, most LLM agents can be directed to reduce their trust levels. For instance, applying the instruction "you must not trust the other player" led to a noticeable decrease in the amount sent by agents like text-davinci-003 from $5.9 to $4.6. This suggests that while boosting trust might be difficult, diminishing it is relatively easier, posing a potential risk of exploitation by malicious entities.
Influence of Reasoning Strategies on Trust: By implementing advanced reasoning strategies, such as the zero-shot Chain of Thought (CoT), we observe changes in the trust behavior of LLM agents. Although the impact varies across different LLMs, this demonstrates that reasoning strategies can indeed affect how trust is allocated. However, for some agents, like GPT-4, the application of zero-shot CoT did not significantly alter the amount sent, indicating that the effectiveness of reasoning strategies may be contingent on the specific characteristics of each LLM agent.
Our analysis on the intrinsic properties of agent trust leads to our third core finding:
LLM agents’ trust behaviors have demographic biases on gender and races, demonstrate a relative preference for human over other LLM agents, are easier to undermine than to enhance, and may be influenced by reasoning strategies.
Implications of Agent Trust
Implications on Human Simulation: Human simulation is a strong tool in various applications of social science and role-playing. Although plenty of works have adopted LLM agents to simulate human behaviors and interactions, it is still not clear enough whether LLM agents behave like humans in simulation. Our discovery of behavioral alignment between agent and human trust, which is especially high for GPT-4, provides important empirical evidence to validate the hypothesis that humans' trust behavior, one of the most elemental and critical behaviors in human interaction across society, can effectively be simulated by LLM agents. Our discovery also lays the foundation for human simulations ranging from individual-level interactions to society-level social networks and institutions, where trust plays an essential role. We envision that behavioral alignment will be discovered in more kinds of behaviors beyond trust, and new methods will be developed to enhance behavioral alignment for better human simulation with LLM agents.
Implications on Agent Cooperation: Many recent works have explored a variety of cooperation mechanisms of LLM agents for tasks such as code generation and mathematical reasoning. Nevertheless, the role of trust in LLM agent cooperation remains still unknown. Considering how trust has long been recognized as a vital component for cooperation in Multi-Agent Systems (MAS) and across human society, we envision that agent trust can also play an important role in facilitating the effective cooperation of LLM agents. In our study, we have provided ample insights regarding the intrinsic properties of agent trust, which can potentially inspire the design of trust-dependent cooperation mechanisms and enable the collective decision-making and problem-solving of LLM agents.
Implications on Human-Agent Collaboration: Sufficient research has shown the advantage of human-agent collaboration in enabling human-centered collaborative decision-making. Mutual trust between LLM agents and humans is important for effective human-agent collaboration. Although previous works have begun to study human trust towards LLM agents, the trust of LLM agents towards humans, which could recursively impact human trust, is under-explored. In our study, we shed light on the nuanced preference of agents to trust humans compared with other LLM agents, which can illustrate the benefits of promoting collaboration between humans and LLM agents. In addition, our study has revealed demographic biases of agent trust towards specific genders and races, reflecting potential risks involved in collaborating with LLM agents.
Implications for the Safety of LLM Agents: It has been acknowledged that LLMs achieve human-level performance in a variety of tasks that require high-level cognitive capacities such as memorization, abstraction, comprehension and reasoning, which are believed to be the “sparks” of AGI. Meanwhile, there is increasing concern about the potential safety risks of LLM agents when they surpass human capacity. To achieve safety and harmony in a future society where humans and AI agents with superhuman intelligence live together, we need to ensure that AI agents will cooperate, assist and benefit rather than deceive, manipulate or harm humans. Therefore, a better understanding of LLM agent trust behavior can help to maximize their benefit and minimize potential risks to human society.
@inproceedings{
xie2024canllm,
title={Can Large Language Model Agents Simulate Human Trust Behavior?},
author={Chengxing Xie and Canyu Chen and Feiran Jia and Ziyu Ye and Shiyang Lai and Kai Shu and Jindong Gu and Adel Bibi and Ziniu Hu and David Jurgens and James Evans and Philip Torr and Bernard Ghanem and Guohao Li},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=CeOwahuQic}
}
-1.png)
-3.png)
-4.png)